Vivado HLS を使ってみた(その4) [FPGA]
浮動小数点のままではさすがにでかいし、精度過剰なので固定小数点化します。
「ap_fixed<>」が固定小数点を扱う型です。bit数とか丸めモードとかサチュレーションモードとか設定できるようになってます。今は適当。floatの代わりに置き換えています。
まずはシミュレーション。fw(小数点以下の精度)が8bitぐらいだと明らかにおかしな画になりますが、12bitぐらいだと見た目は大丈夫そうです。出力されたBMPファイルをバイナリ比較すると1bitぐらい違います。
C Synthesisをかけてみます。
レポートファイル。
データフローとリソース。
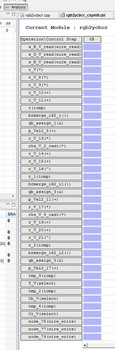
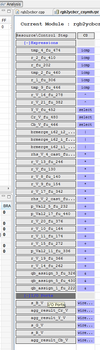
なんとまあ、組み合わせ回路になってしまいました。そりゃそうか。できたHDLを見てみると、ap_startがap_done,ready、各_ap_vldに直結されてます。
実際このままPlanAheadに放り込んでZynqでインプリしたところ、
#define fw 12
YCbCr rgb2ycbcr(RGB s)
{
YCbCr d;
const ap_fixed<2+dw+fw, fw, AP_RND_CONV, AP_SAT> cY [3] = { 0.2126f, 0.7152f, 0.0722f };
const ap_fixed<2+dw+fw, fw, AP_RND_CONV, AP_SAT> cCb[3] = {-0.1146f, -0.3854f, 0.5000f };
const ap_fixed<2+dw+fw, fw, AP_RND_CONV, AP_SAT> cCr[3] = { 0.5000f, -0.4542f, -0.0458f };
const ap_fixed<2+dw+fw, fw, AP_RND_CONV, AP_SAT> op5 = 0.5f * dat;
const ap_fixed<2+dw+fw, fw, AP_RND_CONV, AP_SAT> llim = 0.0f;
const ap_fixed<2+dw+fw, fw, AP_RND_CONV, AP_SAT> ulim = (float)(dat-1);
ap_fixed<2+dw+fw, fw, AP_RND_CONV, AP_SAT> R,G,B;
ap_fixed<2+dw+fw, fw, AP_RND_CONV, AP_SAT> Y,Cb,Cr;
R = s.R;
G = s.G;
B = s.B;
Y = cY [0] * R + cY [1] * G + cY [2] * B;
Cb = cCb[0] * R + cCb[1] * G + cCb[2] * B + op5;
Cr = cCr[0] * R + cCr[1] * G + cCr[2] * B + op5;
if (Y < llim) Y = llim; if (ulim < Y ) Y = ulim;
if (Cb < llim) Cb = llim; if (ulim < Cb) Cb = ulim;
if (Cr < llim) Cr = llim; if (ulim < Cr) Cr = ulim;
d.Y = Y;
d.Cb = Cb;
d.Cr = Cr;
return d;
}
「ap_fixed<>」が固定小数点を扱う型です。bit数とか丸めモードとかサチュレーションモードとか設定できるようになってます。今は適当。floatの代わりに置き換えています。
まずはシミュレーション。fw(小数点以下の精度)が8bitぐらいだと明らかにおかしな画になりますが、12bitぐらいだと見た目は大丈夫そうです。出力されたBMPファイルをバイナリ比較すると1bitぐらい違います。
C Synthesisをかけてみます。
レポートファイル。
===============================================================
== Vivado HLS Report for 'rgb2ycbcr'
================================================================
* Date:
* Version: 2013.1
* Project: rgb2ycbcr
* Solution: solution1
* Product family: zynq zynq_fpv6
* Target device: xc7z020clg484-1
================================================================
== Performance Estimates
================================================================
+ Timing (ns):
* Summary:
+---------+--------+----------+------------+
| Clock | Target | Estimated| Uncertainty|
+---------+--------+----------+------------+
|default | 100.00| 24.80| 12.50|
+---------+--------+----------+------------+
+ Latency (clock cycles):
* Summary:
+-----+-----+-----+-----+---------+
| Latency | Interval | Pipeline|
| min | max | min | max | Type |
+-----+-----+-----+-----+---------+
| 0| 0| 1| 1| none |
+-----+-----+-----+-----+---------+
+ Detail:
* Instance:
N/A
* Loop:
N/A
================================================================
== Utilization Estimates
================================================================
* Summary:
+-----------------+---------+-------+--------+-------+
| Name | BRAM_18K| DSP48E| FF | LUT |
+-----------------+---------+-------+--------+-------+
|Expression | -| 7| 0| 372|
|FIFO | -| -| -| -|
|Instance | -| -| -| -|
|Memory | -| -| -| -|
|Multiplexer | -| -| -| -|
|Register | -| -| -| -|
|ShiftMemory | -| -| -| -|
+-----------------+---------+-------+--------+-------+
|Total | 0| 7| 0| 372|
+-----------------+---------+-------+--------+-------+
|Available | 280| 220| 106400| 53200|
+-----------------+---------+-------+--------+-------+
|Utilization (%) | 0| 3| 0| ~0 |
+-----------------+---------+-------+--------+-------+
+ Detail:
* Instance:
N/A
* Memory:
N/A
* FIFO:
N/A
* Shift register:
N/A
* Expression:
+--------------------------+----------+-------+---+----+------------+------------+
| Variable Name | Operation| DSP48E| FF| LUT| Bitwidth P0| Bitwidth P1|
+--------------------------+----------+-------+---+----+------------+------------+
|r_V_13_fu_246_p2 | * | 1| 0| 0| 18| 8|
|r_V_17_fu_342_p2 | * | 1| 0| 0| 18| 7|
|r_V_8_fu_140_p2 | * | 1| 0| 0| 18| 10|
|r_V_9_fu_154_p2 | * | 1| 0| 0| 18| 8|
|r_V_fu_130_p2 | * | 1| 0| 0| 18| 7|
|rhs_V_2_cast_fu_256_p2 | * | 1| 0| 0| 18| 10|
|rhs_V_4_cast_fu_360_p2 | * | 1| 0| 0| 18| 10|
|p_Val2_11_fu_336_p2 | + | 0| 0| 18| 18| 18|
|p_Val2_17_fu_440_p2 | + | 0| 0| 18| 18| 18|
|p_Val2_5_fu_232_p2 | + | 0| 0| 18| 18| 18|
|r_V_10_fu_164_p2 | + | 0| 0| 28| 28| 28|
|r_V_11_fu_174_p2 | + | 0| 0| 28| 28| 28|
|r_V_15_fu_272_p2 | + | 0| 0| 28| 28| 28|
|Cb_V_fu_466_p3 | Select | 0| 0| 18| 1| 12|
|Cr_V_fu_480_p3 | Select | 0| 0| 18| 1| 12|
|Y_V_fu_452_p3 | Select | 0| 0| 18| 1| 12|
|qb_assign_1_fu_222_p2 | and | 0| 0| 2| 1| 1|
|qb_assign_3_fu_326_p2 | and | 0| 0| 2| 1| 1|
|qb_assign_5_fu_430_p2 | and | 0| 0| 2| 1| 1|
|r_1_fu_306_p2 | icmp | 0| 0| 10| 9| 1|
|r_2_fu_410_p2 | icmp | 0| 0| 10| 9| 1|
|r_fu_202_p2 | icmp | 0| 0| 2| 1| 1|
|tmp_2_fu_460_p2 | icmp | 0| 0| 22| 18| 12|
|tmp_4_fu_474_p2 | icmp | 0| 0| 22| 18| 12|
|tmp_9_fu_446_p2 | icmp | 0| 0| 22| 18| 12|
|brmerge_i62_i1_fu_320_p2 | or | 0| 0| 2| 1| 1|
|brmerge_i62_i2_fu_424_p2 | or | 0| 0| 2| 1| 1|
|brmerge_i62_i_fu_216_p2 | or | 0| 0| 2| 1| 1|
|r_V_16_fu_278_p2 | xor | 0| 0| 40| 28| 29|
|r_V_21_fu_382_p2 | xor | 0| 0| 40| 28| 29|
+--------------------------+----------+-------+---+----+------------+------------+
|Total | | 7| 0| 372| 402| 337|
+--------------------------+----------+-------+---+----+------------+------------+
* Multiplexer:
N/A
* Register:
N/A
================================================================
== Interface
================================================================
* Summary:
+------------------------+-----+-----+------------+-----------------+--------------+
| RTL Ports | Dir | Bits| Protocol | Source Object | C Type |
+------------------------+-----+-----+------------+-----------------+--------------+
|ap_start | in | 1| ap_ctrl_hs | rgb2ycbcr | return value |
|ap_done | out | 1| ap_ctrl_hs | rgb2ycbcr | return value |
|ap_idle | out | 1| ap_ctrl_hs | rgb2ycbcr | return value |
|ap_ready | out | 1| ap_ctrl_hs | rgb2ycbcr | return value |
|agg_result_Y_V | out | 8| ap_vld | agg_result_Y_V | pointer |
|agg_result_Y_V_ap_vld | out | 1| ap_vld | agg_result_Y_V | pointer |
|agg_result_Cb_V | out | 8| ap_vld | agg_result_Cb_V | pointer |
|agg_result_Cb_V_ap_vld | out | 1| ap_vld | agg_result_Cb_V | pointer |
|agg_result_Cr_V | out | 8| ap_vld | agg_result_Cr_V | pointer |
|agg_result_Cr_V_ap_vld | out | 1| ap_vld | agg_result_Cr_V | pointer |
|s_R_V | in | 8| ap_none | s_R_V | scalar |
|s_G_V | in | 8| ap_none | s_G_V | scalar |
|s_B_V | in | 8| ap_none | s_B_V | scalar |
+------------------------+-----+-----+------------+-----------------+--------------+
データフローとリソース。

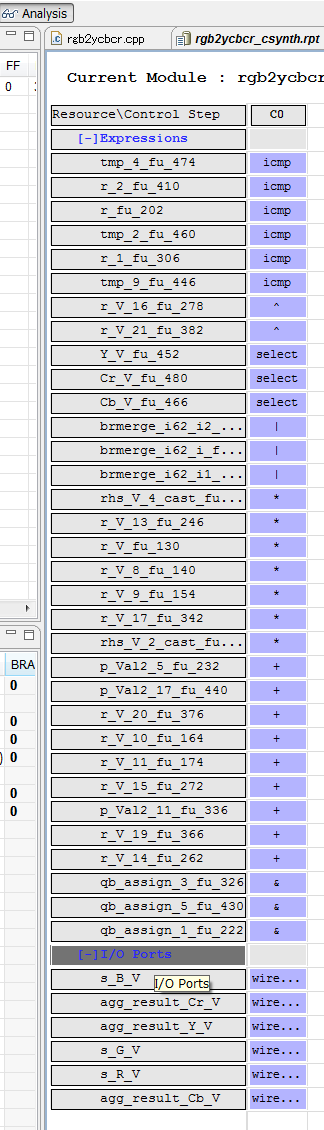
なんとまあ、組み合わせ回路になってしまいました。そりゃそうか。できたHDLを見てみると、ap_startがap_done,ready、各_ap_vldに直結されてます。
実際このままPlanAheadに放り込んでZynqでインプリしたところ、
Number of DSP48E1s 9 out of 220 4%
Number of External IOBs 55 out of 200 27%
Number of LOCed IOBs 0 out of 55 0%
Number of Slices 18 out of 13300 1%
Number of Slice Registers 0 out of 106400 0%
Number used as Flip Flops 0
Number used as Latches 0
Number used as LatchThrus 0
Number of Slice LUTS 60 out of 53200 1%
Number of Slice LUT-Flip Flop pairs 60 out of 53200 1%
DSPリソースがHLSの計算より多い。多分0.5倍が最適化されずに乗算器が実装されたんでしょう。速度は約21[ns]と若干速いですがほぼ予想値通りです。2013-04-24 21:20
nice!(0)
コメント(0)
トラックバック(0)




コメント 0